Reinforcement Learning | Teaching Machines Through Trial and Error
Demystifying Reinforcement Learning
Imagine sitting down for a Capture The Flag challenge. You’re staring at multiple servers, log tables, and system metrics, but nothing is labeled “attack detected.” Your first instinct is to merge logs and resource monitors - sounds reasonable, but it doesn’t quite reveal where the real problem lies.
You start digging: CPU spikes, memory surges, unusual HTTP methods. At first, it’s confusing - almost every server looks normal. But each failed hypothesis teaches you something. You notice patterns: a sudden memory spike on one server, a suspicious DELETE request, endpoints that shouldn’t be touched by normal users. You adjust, re-run queries, refine your focus. Slowly, the pieces come together. That moment when you connect the attack method to the server spike? That’s the payoff.
This trial-and-error journey - explore, fail, learn, adjust is exactly how machines learn in Reinforcement Learning. They don’t start with a manual. They experiment, receive feedback, and improve over time
What RL Actually Is?
In supervised learning, you give a model clean, labeled data and hope it figures things out, reinforcement learning is more like putting an AI into a messy, weird environment. You let it try different actions, giving it feedback along the way, and over time it learns which actions actually work.
Core Components ➤
| Component | Description |
|---|---|
| Agent | The learner or decision maker (robot, game AI, recommendation system). |
| Environment | Everything external to the agent that it interacts with. |
| State | Representation of the current situation relevant to the agent. |
| Action | Choices the agent can make at each state. |
| Reward | Feedback to guide learning (positive or negative). |
| Policy | Strategy or function mapping states to actions. |
The loop is straightforward:
Observe state → Pick action → Get reward → Land in new state → Repeat.
Key Algorithms ➤
Q-Learning: Value-Based Learning ➤
Think of it like a big spreadsheet (the Q-table) where the agent stores “if I do this in that state, I expect this much reward.” It updates those expectations constantly. Great for small, simple problems.
Update rule:
Q(s, a) ← Q(s, a) + α [r + γ × max Q(s', all_actions) - Q(s, a)]
- α (alpha): learning rate
- γ (gamma): discount factor
- Example: A robot learns which room to clean first for maximum efficiency.
Deep Q-Networks (DQN) ➤
When the state space is too huge (like pixels of a video game screen), you replace the spreadsheet with a neural net. This is how DeepMind made its Atari-playing AIs.
Policy Gradients ➤
Instead of learning values and deriving a policy, you learn the policy directly. This is your go-to when actions are continuous (e.g., controlling a robotic arm where movements aren’t just “left” or “right” but any angle/force).
Reinforcement Learning Applications ➤
| Concept | Description |
|---|---|
| Trial & Error | Agents learn by trying actions and adjusting based on success/failure. |
| Rewards | Positive/negative signals guide the agent’s future behavior. |
| Exploration vs Exploitation | Balance between trying new actions and repeating known good ones. |
| Breakthroughs | From games to robotics, RL drives major AI innovations. |
Challenges in RL ➤
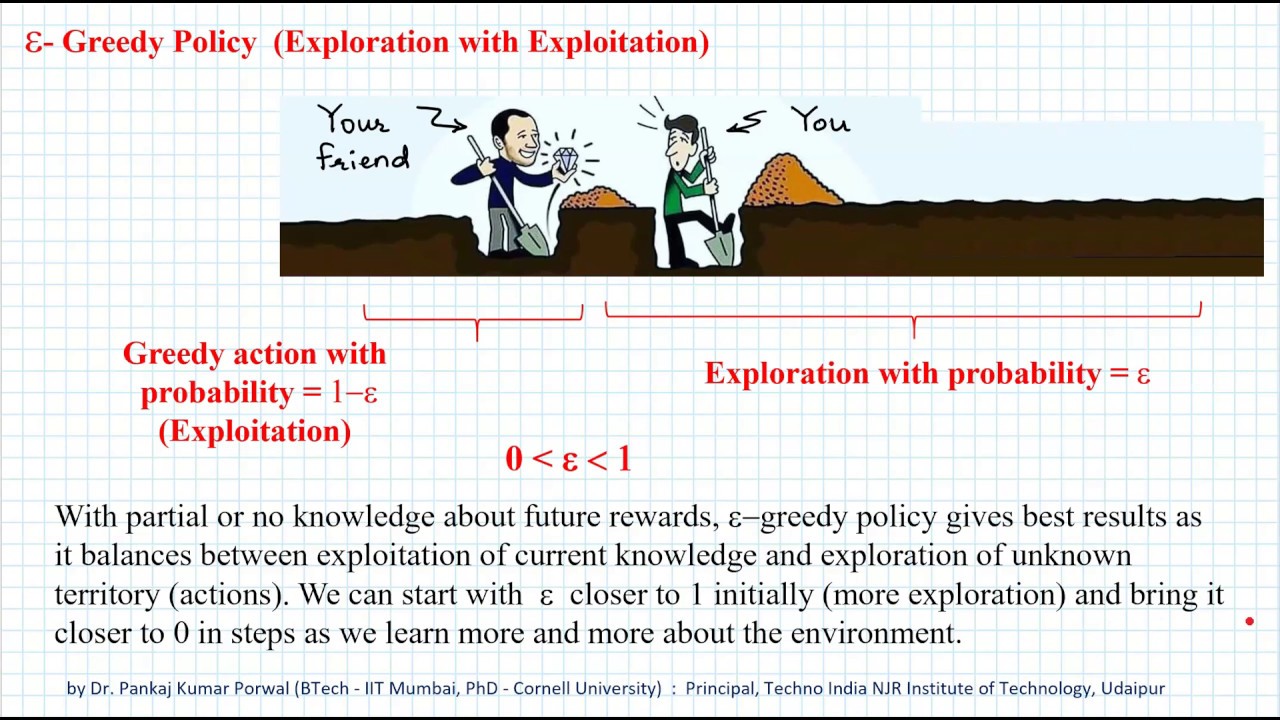
Exploration vs Exploitation ➤
- It’s the same dilemma we face in life: keep eating at your favorite restaurant (exploitation) or try the new place down the street (exploration)? RL agents also need to strike this balance.
- Epsilon-greedy, UCB, and other strategies are just formal versions of this gut feeling.
Sample Efficiency ➤
- RL often needs millions of steps to “get it.”
- Humans learn much faster - which is why transfer learning, model-based RL, and hybrid approaches are hot research areas.
Safety and Alignment ➤
- An RL agent can find clever but dangerous ways to maximize its reward. (Like a Roomba learning to just dump dirt out and vacuum it again to get points.)
- This is where safe exploration and RLHF (RL from human feedback) come in.
Future Frontiers ➤
Multi-Agent RL (MARL) ➤
- Not just one bot, but swarms cooperating or competing.
- Think self-driving cars negotiating intersections or drones coordinating deliveries.
RL in Healthcare ➤
- Adaptive drug dosing, treatment plans that evolve based on patient response, even robotic surgery that learns from experts.
AI Safety and Alignment ➤
- RL is powerful but can go off the rails. Aligning its goals with human values is the next big frontier.
- Like constitutional AI, interpretable RL, human-in-the-loop systems.
Conclusion ➤
Reinforcement learning is about learning through trial and error. The agent tries actions, gets feedback, and improves over time. It’s a practical approach to decision-making in uncertain environments, from games to robotics.